As empresas afirmam que imagens sintéticas podem fazer variedade nos conjuntos de dados, mas correm riscos funcionais e morais.
Salve esta história
Salve esta história
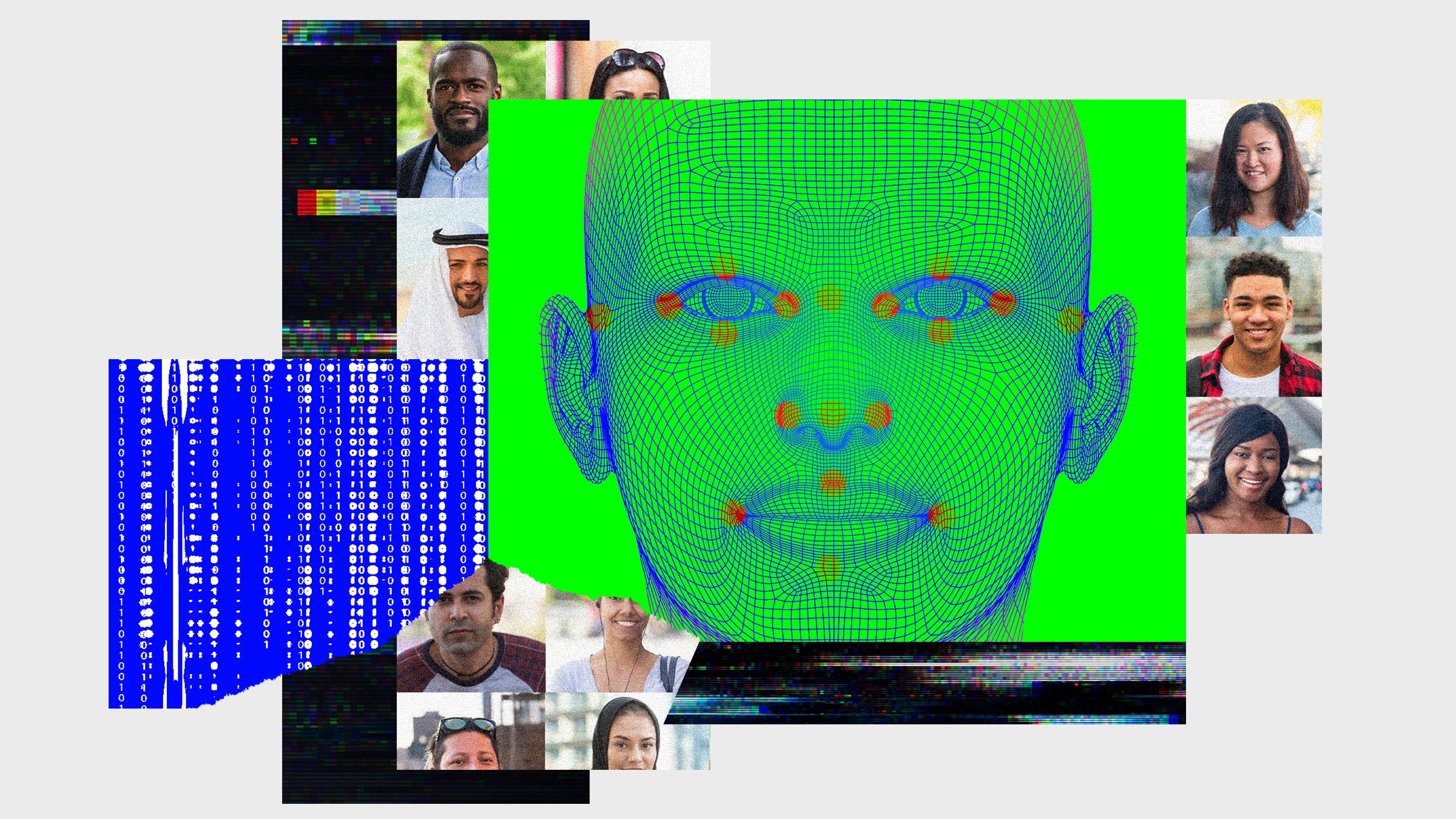
Armado com fé no potencial generativo da tecnologia, o crescente grupo de pesquisadores e empresas procura resolver o problema do viés na IA, criando imagens artificiais de pessoas de cores. Os apoiadores dessa idéia argumentam que os geradores que operam com base na IA podem eliminar lacunas nos bancos de dados existentes dessas imagens, complementand o-as com imagens sintéticas. Alguns pesquisadores usam a arquitetura de aprendizado de máquina para criar novas raças nas fotografias existentes de pessoas para “equilibrar a distribuição étnica” nos bancos de dados. Outros, como a mídia gerada e o Laboratório Qoves, usam tecnologias semelhantes para criar retratos completamente novos para seus bancos, “Criando … rostos de todas as raças e grupos étnicos”, como dizem no Laboratório de Qoves para garantir “conjunto realmente justo de dados sobre pessoas “. Na sua opinião, essas ferramentas eliminarão o viés dos dados, criando barato e efetivamente uma variedade de imagens no comando.
O problema que esse techno está tentando resolver é muito importante. Existem muitos erros na inteligência artificial: ele desbloqueará o telefone da pessoa errada, porque não pode distinguir entre os rostos dos asiáticos, acusa falsamente as pessoas de crimes que eles não cometeram e levam os negros para os gorilas. Essas falhas impressionantes não são anomalias, mas as consequências inevitáveis dos dados nos quais a IA são treinados, na maioria das vezes consistindo em brancos e homens, o que torna essas ferramentas imprecisas para todos que não se encaixam nesse arquétipo estreito. Em teoria, a solução para o problema é simples: só precisamos criar um conjunto mais diversificado de materiais educacionais. No entanto, na prática, isso acabou sendo uma tarefa incrivelmente demorada devido à escala dos dados de origem que requer esses sistemas, bem como a escala de omissões existentes nos dados (IBM Study, por exemplo, mostrou que seis Das oito pessoas conhecidas sobre pessoas são mais de 80 % de rostos justos de pele justa). Assim, a possibilidade de criar uma variedade de conjuntos de dados sem seleção manual é tentadora.
No entanto, após um exame mais detalhado de como essa proposta pode afetar nossos instrumentos e nossas relações com eles, as longas sombras dessa solução aparentemente conveniente começam a adquirir esboços assustadores.
A visão computacional de uma forma ou de outra foi desenvolvida a partir de meados do século XX. Inicialmente, os pesquisadores tentaram criar ferramentas de cima para baixo, definindo manualmente as regras (“o rosto humano tem dois olhos simétricos”) para identificar a classe desejada de imagens. Essas regras foram transformadas em uma fórmula de computação e depois programadas em um computador para procurar pixels correspondentes ao objeto descrito. No entanto, essa abordagem acabou sendo quase malsucedida devido a uma enorme variedade de objetos, ângulos e condições de iluminação que podem fazer uma fotografia, bem como devido à complexidade da tradução de regras simples em fórmulas coerentes.
Inscrever-se para
Inscrev a-se na Wired e mantenh a-se a par de todas as suas idéias favoritas.
Com o tempo, um aumento no número de imagens públicas possibilitou o uso do processo de aprendizado de máquina no princípio de “de baixo para cima”. Nesta metodologia, as matrizes de massa de dados marcadas são recebidas no sistema. Graças ao “aprendizado controlado”, o algoritmo recebe esses dados e se ensina a distinguir entre as categorias necessárias determinadas pelos pesquisadores. Esse método é muito mais flexível que o método “de cima para baixo”, pois não depende das regras que podem mudar em diferentes condições. Estudando em vários dados iniciais, a máquina pode determinar as semelhanças entre imagens de uma determinada classe sem uma indicação clara dessas semelhanças, o que permite criar um modelo muito mais adaptado.
No entanto, o método “de baixo para cima” não é perfeito. Em particular, esses sistemas são amplamente limitados pelos dados que lhes são fornecidos. De acordo com o escritor técnico Rob Horning, esse tipo de tecnologia “sugere um sistema fechado”. É difícil para eles extrapolar dados fora dos parâmetros especificados, o que leva a uma limitação do desempenho quando enfrentam objetos de que não são muito bem treinados. Por exemplo, devido às discrepâncias nos dados, o sistema FaceEtect da Microsoft teve uma porcentagem de 20 % de erros para mulheres de pele escura, enquanto a porcentagem de erros para homens brancos foi de cerca de 0 %. A influência desses erros no treinamento de produtividade é a razão pela qual os especialistas em ética tecnológica começaram a pregar a importância dos conjuntos de dados e por que empresas e pesquisadores estão na corrida para resolver esse problema. Como um ditado popular no campo da IA diz: “Fluxos de lixo, derramamentos de lixo”.
Essa regra se aplica igualmente aos geradores de imagens, que também requerem grandes matrizes de dados para ensinar a arte de um desempenho fotorrealista. A maioria das pessoas modernas usa redes adversárias generativas, ou Gans) como sua arquitetura básica. O GAN é baseado em duas redes – um gerador e um discriminador que interage entre si. Enquanto o gerador cria imagens baseadas em ruído, o discriminador tenta resolver as falsificações geradas a partir de imagens reais fornecidas pelo conjunto de treinamento. Com o tempo, essa “rede adversária” permite que o gerador melhore e crie imagens que o discriminador não pode identificar como falso. Os dados iniciais são a âncora desse processo. Historicamente, dezenas de milhares de imagens são necessárias para obter resultados bastante realistas, o que indica a importância de vários conjuntos de treinamento para o desenvolvimento correto dessas ferramentas.
Mais popular
A ciência
Uma bomba demográfica de uma ação lenta está prestes a atingir a indústria de carne bovina
Matt Reynolds
Negócios
Dentro do complexo supe r-secreto Mark Zuckerberg no Havaí
Gatrine Skrimjor
Engrenagem
Primeira olhada em Matic, um aspirador de robô processado
Adrienne co
Negócios
Novas declarações de Elon Mask sobre a morte de um macaco estimulam novos requisitos para a investigação da SEC
Dhruv Mehrotra
No entanto, isso significa que o plano para o uso de dados sintéticos para eliminar lacunas na variedade é baseado na lógica circular. Como tecnologias de visão computacional que eles são chamados ao suplemento, esses geradores de imagens não podem sair desse “sistema fechado”. A solução proposta apenas empurra o problema um passo para trás, pois não faz nada para eliminar os preconceitos estabelecidos nos dados de origem nos quais os geradores estudam. Sem a eliminação preliminar dessas deficiências, os geradores de imagem desenvolvidos por nós apenas simularão e refletirão restrições existentes e não as eliminarão. Não podemos usar essas tecnologias para criar o que ainda não está em dados de treinamento.
Como resultado, as imagens que criam podem reforçar os preconceitos que procuram erradicar. Por exemplo, as “transformações raciais” demonstradas no trabalho da IJCB resultaram em imagens perturbadoras que lembram rostos pretos e amarelos. Outro estudo, realizado na Universidade Estadual do Arizona, descobriu que os GANs, quando encarregados de gerar os rostos dos professores de engenharia, simultaneamente iluminaram a “cor da pele dos rostos não brancos” e converteram “características faciais femininas em masculinas”. Na falta de diversidade, estes geradores foram incapazes de criá-la – ex nihilo nihil fit, nada vem do nada.
Mais importante ainda, os preconceitos contidos nestas imagens sintéticas serão incrivelmente difíceis de detectar. Afinal, os computadores não “vêem” da mesma forma que nós. Mesmo que os rostos criados parecessem perfeitamente normais para nós, eles ainda poderiam conter idiossincrasias ocultas que eram visíveis ao computador. Num estudo, a IA foi capaz de prever a raça de um paciente a partir de imagens médicas que não continham “nenhuma evidência de raça discernível para especialistas humanos”, de acordo com o MIT News. Além disso, os pesquisadores até tentaram, retrospectivamente, determinar o que exatamente o computador estava observando para fazer essas distinções.
Essas imagens sintéticas também podem conter detalhes que podem distorcer essas ferramentas e são completamente invisíveis ao olho humano. Se estes sistemas associassem traços sintéticos ocultos a pessoas não-brancas, tornar-se-iam susceptíveis a toda uma série de falhas com as quais não seríamos capazes de lidar porque não seríamos capazes de ver as diferenças relevantes – uma chave invisível nas engrenagens .
Há uma contradição irónica escondida nestas imagens sintéticas. Embora esta estratégia se destine a capacitar e proteger grupos marginalizados, não inclui quaisquer pessoas reais no processo de representação. Em vez disso, substitui corpos, rostos e pessoas reais por outros criados artificialmente. Ao considerar os méritos éticos desta proposta, tal substituição deveria fazer-nos pensar – sobretudo devido à longa e complexa história de apagamento online.
Mais popular
A ciência
Uma bomba demográfica de uma ação lenta está prestes a atingir a indústria de carne bovina
Matt Reynolds
Negócios
Dentro do complexo supe r-secreto Mark Zuckerberg no Havaí
Gatrine Skrimjor
Engrenagem
Primeira olhada em Matic, um aspirador de robô processado
Adrienne co
Negócios
Novas declarações de Elon Mask sobre a morte de um macaco estimulam novos requisitos para a investigação da SEC
Dhruv Mehrotra
Os primeiros teóricos da Internet estavam bem cientes de como a vida digital pode mudar nossa compreensão da corrida. Embora alguns deles tenham sido ajustados cuidadosamente otimistas, acreditando que essas possibilidades poderiam ser divulgadas para grupos marginalizados, os críticos mais perspicazes eram céticos, observando que essa flexibilidade era principalmente para aqueles que já possuíam poder. Lisa Nakamura, por exemplo, escreveu nos anos 90 sobre o “turismo da identidade”, que ela observou em bat e-papos, sobre como o anonimato do espaço digital permitiu que os usuários brancos “se entregassem aos sonhos de cruzamento temporário e recreativo de bordas raciais” , levar pessoas raciais com os nomes de esses usuários, como a “boneca asiática”, “convidado da gueixa” e “Virgo Taiwan”. Em vez de dar às pessoas a oportunidade de tratar realidades complexas e difíceis de identidade e suas consequências, a vida digital, ao que parece, especialmente extrai esses recursos de suas condições reais e as transforma em mercadorias.
À medida que a Internet se espalha nas décadas subsequentes, esse comportamento encontrou uma expressão crescente. De acordo com Rosa Boshie, a economia da influência tornou possível usar figuras digitais como Lil Michela, “A identidade da raça mista como uma forma de poder e cache” – as marcas tiveram a oportunidade de lucrar com um “facilmente reconhecível, Cantor de cores oprimido “sem a necessidade de trabalhar com essa mulher. Enquanto isso, os usuários brancos poderiam participar de novos formulários refletidos nas tecnologias digitais devido à plasticidade do corpo digital, usando ferramentas como filtros de face e Photoshop para racificar sua aparência por uma questão de curtidas. Mais recentemente, os ecos da prática repugnante de escravidão novamente se manifestaram no aparelho proprietário da NFT, que permitiu comprar, vender e possuir avatares raciais por prazer. Em cada um desses casos, a raça foi virtualizada, transformand o-se em um recurso livremente flutuante que pode ser anexado a qualquer pessoa ou qualquer coisa, independentemente de sua posição real, geralmente para obter lucro.
As imagens sintéticas de cores agem de acordo com o mesmo esquema, separando a corrida daqueles que a vivem – transformand o-a em dados puros que podem ser manipulados. Representantes de minorias serão transformados em material passivo, incapazes de exigir justiça e serão forçados a aparecer na chamada para preencher os orifícios em nossos mapas de informações. De muitas maneiras, essa estratégia toma a lógica de abstração e conformidade, revelada por Nakamura, e a incorpora na arquitetura fundamental de nossas tecnologias emergentes. Lendo o símbolo digitalizado, nos permitimos esquecer o referente em toda a sua realidade específica e pressionada.
A idéia de que podemos usar imagens sintéticas para o treinamento de nossa IA é uma “fé cômica no technofix”, que a teórica Donna Haraway caracteriza como uma dimensão chave do discurso moderno. Confiante em seu próprio raciocínio rápido – a capacidade de resolver problemas fundamentais com a ajuda de outra ferramenta – propomos construir uma trava tecnológica na areia. Esta é uma estratégia presa com nada mais que raciocínio circular e motivado principalmente pela apatia. Seguir ela não apenas minará o funcionamento potencial desses sistemas, mas também significará que sucumbimos à preguiça moral. Pod e-se esperar que, nesse momento, já tínhamos aprendido a lição. Maneiras curtas levam a atrasos de longo prazo.


